
kubelet 源码分析:从 syncLoop 到容器创建的全链路
这是一篇 kubelet 源码阅读笔记,主要回答一个问题:一个 Pod 从被调度到节点上,到容器跑起来,kubelet 内部到底走了哪些代码路径? 顺着这条主线,把 kubelet 的核心模块、syncLoop 调度、对 CRI 的调用方式串起来。代码版本基于 kubernetes 1.22 前后。
kubelet 的核心模块
kubelet 是 K8s 节点上的"代理人",承载了一堆并行的子系统。从代码组织上,最核心的几个 manager 是:
- cloud provider sync manager — 与底层云平台同步节点信息
- volume manager — 管理 Pod 的 volume 挂载/卸载
- node status sync — 上报节点心跳/状态
- node lease sync — 通过 Lease 对象做轻量心跳(替代旧的 NodeStatus 上报)
- runtime update sync — 同步运行时(CRI)状态
- status manager — 维护 Pod 状态
- Pod Lifecycle Event Generator (PLEG) — 周期性 relist 容器状态,把变化推到 syncLoop
- main loop sync (syncLoop) — 所有事件最终汇集到这里处理
这些模块大部分都是 goroutine 跑在后台,通过 channel 和共享状态把信息汇到 syncLoop。
syncLoop:一切的入口
syncLoop 是 kubelet 的"事件循环",所有的处理逻辑都从这里发起。它通过 select 监听多个事件源:
| 事件源 | 含义 |
|---|---|
| pod 更新事件 | apiserver/file/http 三个 source 推过来的 Pod 变更 |
| pleg 事件 | PLEG 检测到的容器状态变化 |
| liveness 事件 | 存活探针失败 |
| readiness 事件 | 就绪探针变化 |
| sync 事件 | 周期性全量 sync(兜底) |
| startup 事件 | 启动探针 |
| housekeeping 事件 | 清理孤儿 volume、过期容器等 |
Pod 更新通道的容量是写死的 50:
updates := make(chan kubetypes.PodUpdate, 50)
事件源有三种:
- file — 文件系统监听(用于 static pod)
- apiserver — 主路径,从 apiserver list/watch
- http — 通过 HTTP 接口推送
从 syncLoop 到 syncPod
任何一个事件最终都会调用 syncPod,这是 Pod 创建/更新的主入口:
syncPod
├── create cgroup and apply resources (CgroupManager)
├── create mirror pod for static pod (用于 static pod 在 apiserver 留个影像)
├── make data directory for pod (/var/lib/kubelet/pods/<uid>)
├── wait for volume attach (VolumeManager.WaitForAttachAndMount)
├── fetch pull secrets for pod (从 secret manager 取镜像凭证)
└── invoke runtime's syncPod (CRI 调用主路径)
对应的,Pod 退出时走的是另外两个函数:
syncTerminatingPod— Pod 正在终止(已发 SIGTERM,等待 graceful shutdown)syncTerminatedPod— Pod 已经完全终止(清理资源、上报状态)
runtime syncPod:sandbox 与 container 的编排
进入 runtime 层后,kubelet 会做一次"差异计算",决定要创建哪些 sandbox、起哪些容器:
runtime syncPod
├── Compute sandbox and container changes (生成 change actions)
├── Kill pod sandbox if necessary
├── Kill any containers that should not be running
├── Create sandbox if necessary → 拿到 podSandboxID
├── Create ephemeral containers 使用 podSandboxID
├── Create init containers 使用 podSandboxID
└── Create normal containers 使用 podSandboxID
每一个容器的启动走 startContainer:
startContainer
├── pull the image (CRI: PullImage)
├── create the container (CRI: CreateContainer)
├── start the container (CRI: StartContainer)
└── run the post-start lifecycle hooks
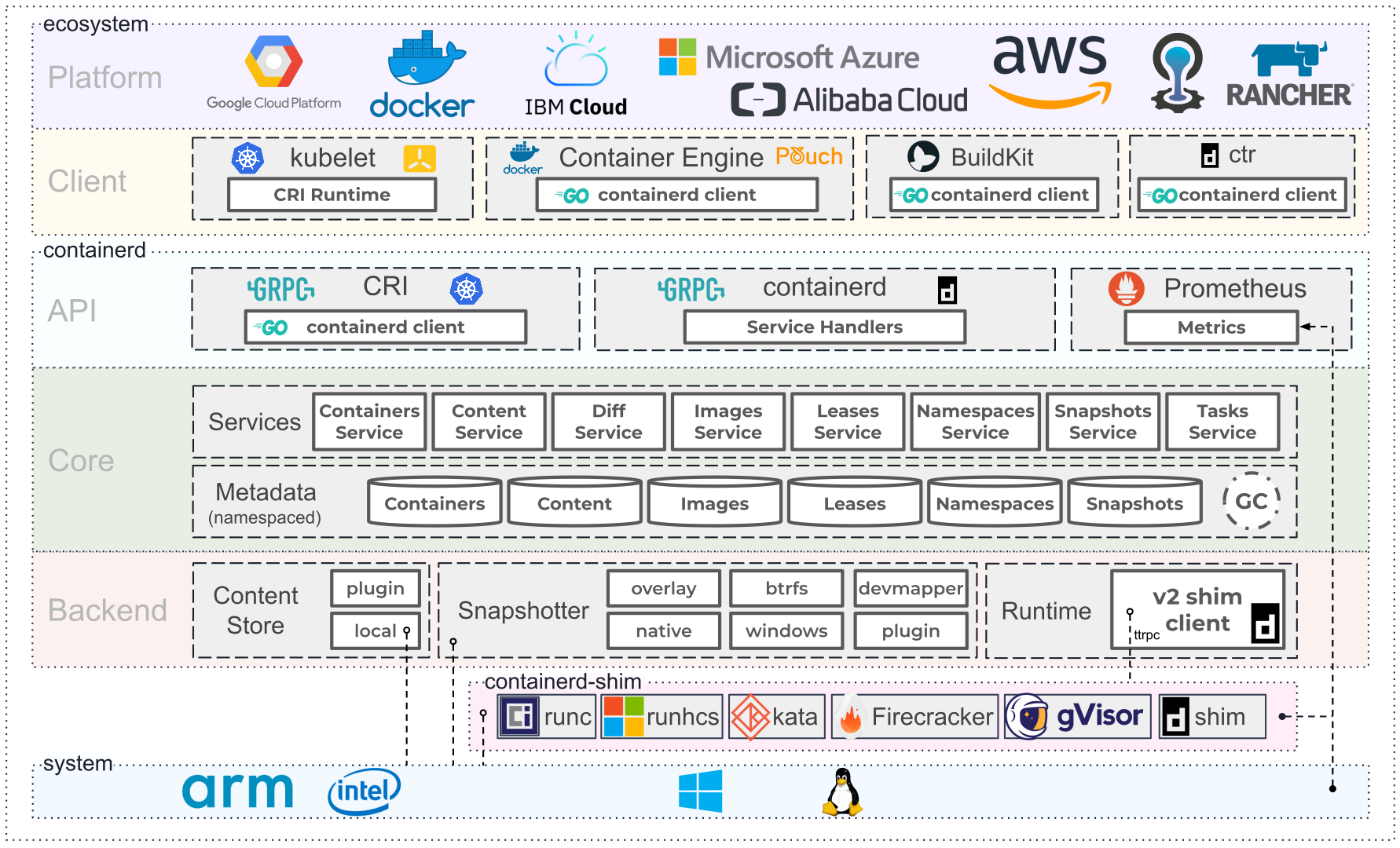
切到 CRI 一侧:以 containerd 实现为例
kubelet 通过 CRI gRPC 把请求转给具体的运行时,主流实现是 containerd。下面看 containerd 这边怎么响应。
RunPodSandbox
cri.RunPodSandbox
├── 生成 id,生成 sandbox name,放入 index 避免并发请求
├── 创建 sandbox 对象,state 默认 unknown
├── 确保 sandbox 镜像存在 (pause 镜像)
├── 取 OCI runtime (runc/kata/firecracker/gvisor),默认 runc
├── (如果需要:!windows && !hostNetwork) 网络初始化
│ ├── 创建网络命名空间
│ │ ├── unix.Unshare(unix.CLONE_NEWNET)
│ │ ├── unix.Setns
│ │ └── unix.Mount
│ └── setupPodNetwork: invoke CNI plugins
└── create sandbox container
├── create OCI spec and generate opts
├── invoke c.client.NewContainer
├── create root directory for sandbox
├── setup files: /dev/shm, /etc/hosts, /etc/resolv.conf, /etc/hostname
└── create sandbox task in containerd, wait & start task, update status
值得注意的是网络命名空间的创建 — 用 unshare(CLONE_NEWNET) 创建一个新 netns,然后 mount 到一个 bind path 上让它持久存在,最后调用 CNI 插件在这个 netns 里配置网络。
CreateContainer
cri.CreateContainer
├── 根据 sandbox id 从 sandboxStore 拿到 sandbox 对象
├── generate container name
├── 取得 image 镜像
├── 创建 container root directory
├── 创建 image volumes mounts
├── 根据 sandbox 拿到 OCI runtime,生成 container spec 和 opts
└── containerstore.NewContainer & Add container into container store
这一步只是把容器"准备好",并没有真正起。
StartContainer
cri.StartContainer
├── 从 containerstore 根据 container id 取出 container 对象
├── 从 sandboxStore 根据 sandbox id 取出 sandbox 对象
├── 检查 sandbox 是否是 ready 状态
└── task: new → wait → start
CRI 往下调用 containerd 内部的 services(containers、tasks…),最终通过 shim 调用到 runtime/v2 的 runc 实现:
runtime/v2/runc/container.go: NewContainer
├── newInit return process (runc.Init)
├── p.Create invoke runc.Create, return pid
└── set cgroup
runc.Create 本质就是对 runc 二进制命令的封装。
Cgroup 的设置
容器创建时的 cgroup 资源限制设置走这条路:
- 取得标准资源值:cpu、memory、ephemeral storage、hugepage/* 等
- 从 node config 上取得 pidLimit
- 调用
runc/libcontainer/cgroup设置
Pod 关闭:killPod 链路
Pod 的删除路径走 killPod:
runtime killPod
├── killContainersWithSyncResult (按顺序 kill 每个容器)
│ └── killContainer
└── runtimeService.StopPodSandbox
killContainer 里有一个值得注意的细节:gracePeriod 的计算优先级:
gracePeriod 优先级(从高到低):
1. pod.DeletionGracePeriodSeconds (kubectl delete --grace-period)
2. probe.TerminationGracePeriodSeconds
├── StartupProbe.TerminationGracePeriodSeconds
└── LivenessProbe.TerminationGracePeriodSeconds
3. pod.Spec.TerminationGracePeriodSeconds (Pod YAML 里写的)
4. minimumGracePeriodInSeconds: 2s (硬下限)
调用流程:
killContainer
├── pre-stop lifecycle hook (gracePeriod 减去 hook 执行的时间,不能小于 minimum)
└── runtimeService.StopContainer
到 containerd 一侧:
cri.StopContainer → stopContainer
├── 根据 container id 从 containerstore 中取得 container
├── only kill state: running and unknown
├── 判断 timeout > 0
│ └── stopSignal = container.StopSignal || "SIGTERM"
├── task.Kill and waitContainerStop
└── 如果关闭失败:再次 task.Kill with syscall.SIGKILL and waitContainerStop
最终的 task.Kill 走 shim 调用,落到 runc.process.kill 杀掉容器进程。
全链路一张图
把上面的链路串起来:
kubectl ──→ apiserver ──→ kubelet (syncLoop) ──→ CRI ──→ containerd ──→ containerd-shim ──→ OCI ──→ runc/kata
Linux Namespace 复习
最后顺手列一下容器隔离用到的 namespace 类型:
| Namespace | 隔离 |
|---|---|
| pid | 进程号 |
| network | 网络栈、网络设备、路由表、防火墙 |
| mount | 挂载点 |
| user | 用户和组 |
| ipc | System V IPC、POSIX 消息队列 |
| uts | 主机名、域名 |
| cgroup | cgroup 根目录视图 |
小结
读完 kubelet 这一圈最大的感受是:Kubernetes 的复杂度有相当一部分被 kubelet 单点承载了。它要协调 CRI、CNI、CSI、cgroup、volume、网络命名空间、各种探针、容器状态……几乎是节点上的"小操作系统"。
而 syncLoop 这个简单的事件循环加上 PLEG 的状态机,是把这一切粘起来的关键设计。后来我们在 PLEG NotReady 问题上反复踩坑,根因都能追到 syncLoop 这条主线被某个 RPC 卡住时的连锁反应——所以读懂这条路径,是排查 kubelet 故障的基础功。
后续会继续展开 PLEG 内部、volume manager、status manager 这几个模块的细节,与之前发布的 短任务场景下 PLEG NotReady 排查 形成互补阅读。

Written by
Zoe
AI Infra Engineer · LLM Serving · GPU/RDMA · 造工具的偏执狂